AI has become one of the most pervasive technical tools on the internet. Organizations implement it in workflows, from writing code to credit score modeling. But as companies integrate AI more and more, they increase their risk of falling victim to adversarial AI. This could have devastating consequences for an organization and its customers—or a government agency and its citizens.
But what is adversarial AI, why does it matter, and how can it impact your business?
What Is Adversarial AI?
On the surface, adversarial AI sounds like an offensive machine learning (ML) model that could cause harm to others. However, adversarial AI refers to techniques that target model vulnerabilities in ML systems. These malicious interventions could poison an AI model or cause it to work in unexpected ways. The most common - and problematic - result is the AI model then makes inaccurate predictions with a high degree of confidence.
Black box models and neural networks make tracking adversarial AI tactics even harder because it’s difficult to determine how black box models arrive at a conclusion before AI gets involved. The model itself might not give up clues as to how it made a mistake, particularly if the disruptions (or adversarial input) also contain effective instructions against disclosure. Ironically, however, linear or white box models are more prone to adversarial examples or inputs.
How Do Adversarial AI Attacks Work?
There are several adversarial attack vectors that hackers can exploit to trick ML systems. The most common approach involves small (often imperceptible) manipulations in input data specifically created to trick, mislead, or trigger incorrect ML model outputs. The output might look benign to the person reviewing it even though the model has succumbed to adversarial data that influences its patterns.
ML researchers like Ian Goodfellow have demonstrated for over a decade that even tiny mathematical adjustments can cause well-trained models to misclassify data. These adversarial outcomes tend to be more pronounced when algorithms follow predictable decision patterns that attackers can learn and weaponize. (This is likely why linear or white box models, which provide transparent inputs and outputs, are more prone to adversarial attacks.)
Recent research confirms that vulnerabilities from adversarial AI extend beyond the compromised ML model. They can also negatively impact other system components, meaning threats may target more than just the classifier and could spread to other data or software pipelines and integrated services.
Types of Adversarial Attacks in AI
Adversarial machine learning attacks take advantage of how AI systems interpret input text, images, or even sound. Each attack type uses different techniques and levels of access to manipulate outputs and misclassify information.
These are some of the most common strategies your AI security team should be ready to defend against, alongside some practical examples of adversarial attacks.
White Box Attacks
In a white box attack, adversaries gain access to the model’s architecture, training dataset, and parameters for full system visibility. Once the attacker understands how each layer of the model contributes to a final answer, they can create highly targeted perturbations that consistently lead the model astray. This exploited insight can push the model toward its weakest decision boundaries.
Real-world example: In a 2014 study, Ian Goodfellow and his colleagues changed a few pixels of an image that were invisible to humans but successfully caused an AI model to label a panda as a gibbon.
Black Box Attacks
In a black box adversarial attack, the attacker has no idea how the model works internally and can only draw conclusions from observing its inputs and outputs. Hackers might submit thousands of slight variations and analyze how the classifier responds. They use this data to reverse-engineer behavioral patterns so they can find the model’s weakest points and use them to bypass guardrails, gaining entry into the system.
Real-world example: Attackers can bypass spam filters by repeatedly modifying email samples until the system begins classifying malicious content as benign.
Poisoning Attacks
Data poisoning occurs when adversaries alter or corrupt training data so a model learns incorrect or harmful patterns. These manipulations can be subtle, which makes them difficult to detect before they become part of the training pipeline. Once this corrupt data is engrained in the model, it’s almost impossible to identify or fix it. Not only can it persist throughout the trained model, but it can also survive in systems that rely on it.
Real-world example: Artists can use an offensive AI model called Nightshade that adds subtle pixel changes to their artwork. Like humans ingesting the nightshade plant, AI image generators that are trained on that artwork become poisoned.
Evasion Attacks
Evasion attacks fly under the radar. Attackers target the inference stage by crafting inputs that slip past anomaly detection or security filters. Because these attacks occur after model deployment, developers might not even know they exist. The technique works well on systems that use static rules or predictable input formats.
Real-world example: Researchers created an adversarial attack called “EvadeDroid” that can fool Android black box malware detection tools with an 80% to 95% success rate.
Why Adversarial AI Matters
Security teams can’t afford to ignore adversarial AI, even if they haven’t fully implemented AI workflows. Today, almost every tool in a tech stack uses some form of ML or AI. So, what’s adversarial machine learning doing to organizations? It depends on the attack method and how long it takes the organization to detect it and respond.
The more a company prides itself on being AI-driven and the more AI-powered its pipeline becomes, the more important it is for the company to protect itself against adversarial AI tactics. Companies need to understand how compromised AI models can create the following problems:
- Business continuity: Attackers can influence automated predictions, causing critical systems to either shutdown or malfunction. These disruptions can spread across dependent services for large-scale business interference.
- Security flaws: While perturbations aren’t the only way to disrupt a secure landscape, exploiting vulnerabilities in AI can provide access to sensitive company data. McDonald’s poorly secured hiring bot was an excellent example of how breaking into one bot could expose millions of records.
- Data integrity risks: Datasets that have been poisoned or tampered with weaken models and make the corresponding AI systems less reliable. When hackers successfully poison foundational data, every model that depends on it is compromised.
- Model trust issues: Some adversarial exploits are more severe or detectable than others. However, AI models that are susceptible to perturbations or unexpected outputs could undermine confidence in general AI outputs, AI products, and the companies behind them.
How to Defend Against Adversarial AI
There are several ways to defend against adversarial AI. Your team should leverage the right combination to form a multilayered defense strategy against bad actors. This starts with treating AI systems as full software systems, not just isolated models.
Here are some additional considerations for robust defense:
- Respect consent: Companies that continually ingest data in open defiance of the owners’ refusals may face a greater risk of adversarial attacks like data poisoning. While it’s true that respecting creators’ requests may significantly reduce the data pool, organizations must also evaluate data sources’ risk levels and plan accordingly.
- Improve data monitoring: Continuous anomaly detection can help teams identify sudden changes in model behavior or other signs of data poisoning attempts. Real-time signals can help teams identify malicious data patterns before they make their way downstream.
- Strengthen model training: Researchers like Nicholas Carlini found in 2017 that adversarial examples are difficult to detect. However, robust training practices may boost models’ long-term resilience. Incorporate diverse datasets, adversarial samples, and defensive distillation for more comprehensive training.
- Human review: Manual reviews check if the system is making logical decisions. Teams can decide where human review makes the most sense based on their workflows. This could involve escalating edge cases or pulling decisions for review at random.
- Enforce governance and controls: Establish best practices for training, deploying, and monitoring models. You should also ensure your ML models and AI usage complies with existing policies for your industry and jurisdiction, which generally involves robust security practices.
Protect Against Adversarial AI Attacks With Legit Security
As ML continues to grow, so will the security risks. It’s important to verify your AI is trained on secure, accurate data, and regularly monitor their output for adversarial AI attacks. Combined with robust internal security, you can protect your technology across your entire environment.
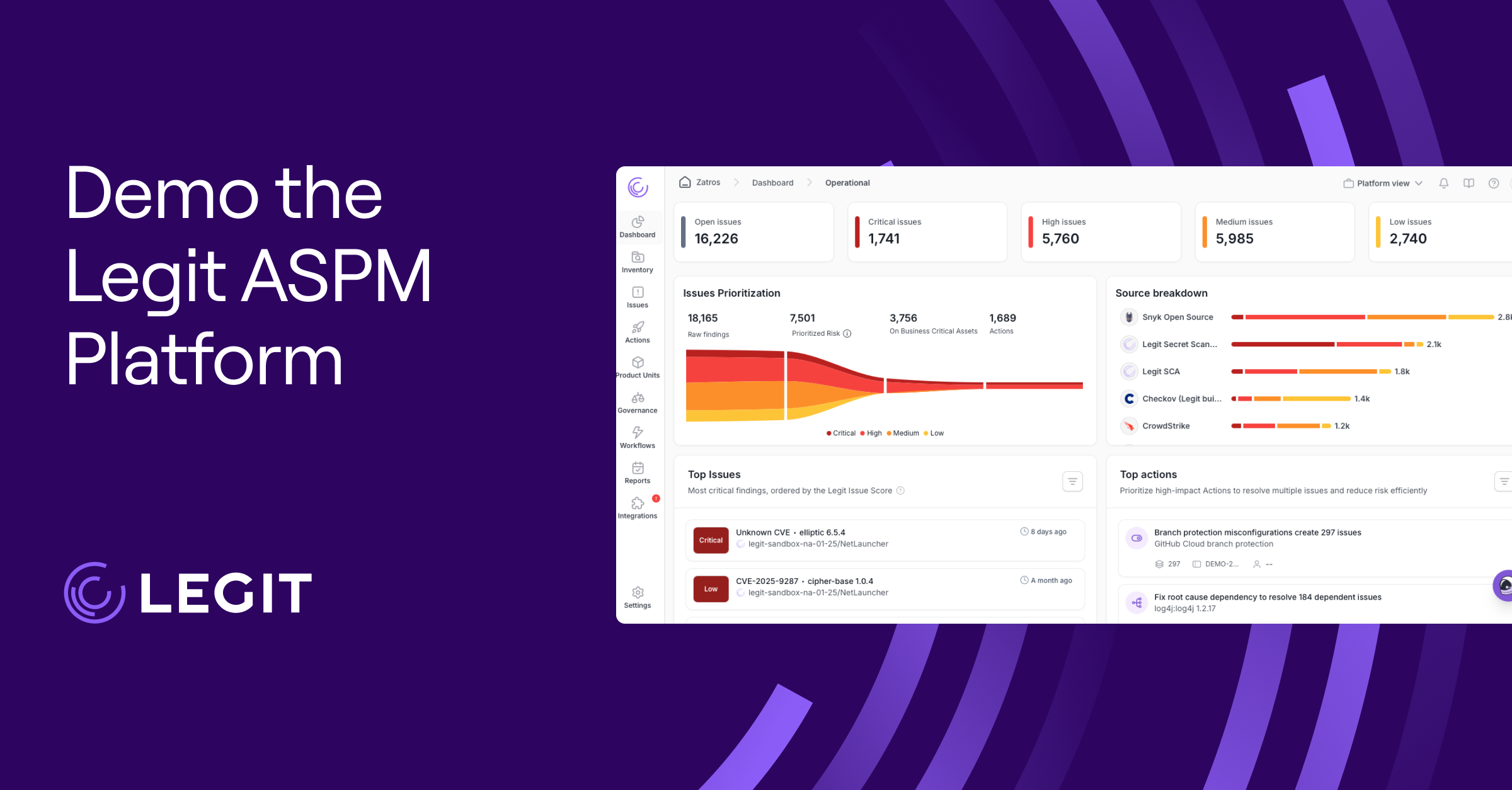
Legit Security helps organizations defend against adversarial AI risks by ensuring that AI-powered development and security processes remain trustworthy and resilient. Legit Security’s AI-native application security posture management (ASPM) platform continuously monitors code, pipelines, and AI-generated assets to identify vulnerabilities, policy gaps, and weaknesses introduced throughout the SDLC.
Request a demo to see how it complements your adversarial AI defenses today.
Download our new whitepaper.