CISA made risk-based prioritization federal policy. That’s the problem we’ve been working on for years.
On June 10, the U.S. Cybersecurity and Infrastructure Security Agency (CISA) issued a new directive on how federal agencies should handle software vulnerabilities. In short, CISA said to stop deciding what to fix first based on a generic severity score and start deciding based on actual risk. Agencies now must ask whether a flaw is genuinely exposed and exploitable before treating it as urgent, which means the old “every critical is a five-alarm fire” approach is officially dead.
Severity was never risk
CVSS measures theoretical severity in a vacuum. It says nothing about whether the asset is exposed, whether the flaw is reachable, whether exploitation can be automated, or whether it sits near anything your business cares about. BOD 26-04 throws that out and judges every vulnerability on four questions: Is it publicly exposed? Is it in the KEV catalog? Can exploitation be automated? Does it give partial or total control? The answers decide whether you patch immediately, in 3 days, 14, 60, or at the next upgrade.
The bottleneck was never volume
The real failure mode isn’t that teams can’t fix enough, it’s that they burn limited capacity on the wrong things. Teams can only remediate a fraction of their open vulnerabilities in any given period. Spend that on high-severity findings that are unreachable, unexposed, or not even deployed, and you didn’t reduce risk, but simply performed compliance theater. A team racing to patch a “critical” in a library that’s buried in a test harness and never ships to production, while a moderate flaw on an internet-facing service quietly waits its turn: that’s the trap CISA’s new directive aims to avoid.
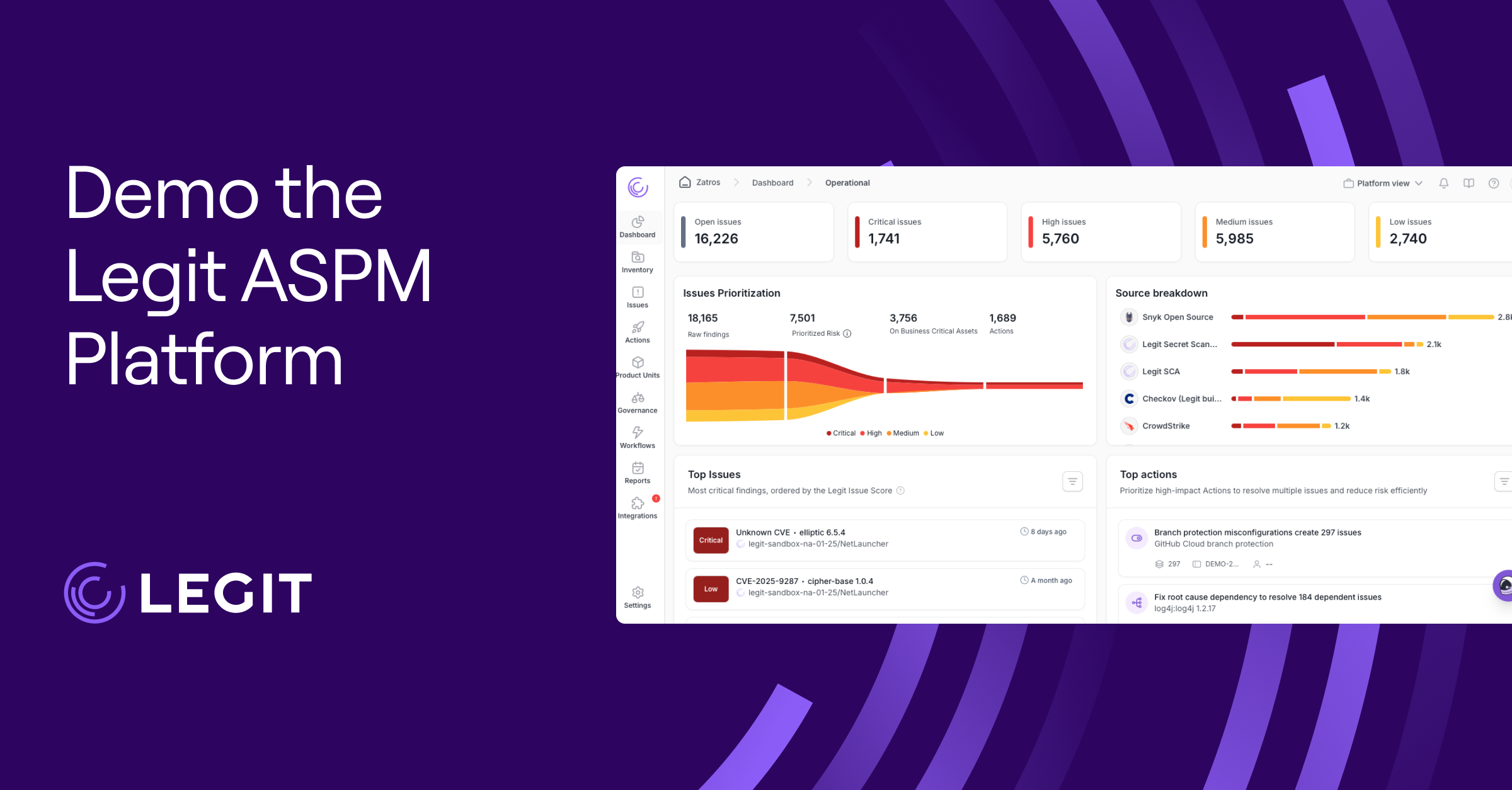
We’ve been computing this for years
This is the problem Legit was built to solve. We take CVSS into account as a signal, but as just one factor in a broader computation: exposure, reachability, exploitation evidence, whether the code is deployed, and business context. A SQL injection flaw in an internal admin tool that two people use behind the VPN gets ranked very differently from the same flaw in a customer-facing payment endpoint. Same vulnerability class, completely different risk, and that’s the call a severity score can’t make.
AI just broke the math further
AI has industrialized the vulnerability lifecycle: exploits built in minutes, the disclosure-to-weaponization window collapsed to hours, and 2026 projected near 59,000 CVEs. You can’t patch your way out of that. And AI isn’t only finding flaws – it’s writing the software, far more of it, far faster, from people who aren’t security engineers. More generated code means more components, more surface area, more vulnerabilities per unit of time. Supply-side risk is accelerating while attacker speed compounds. When the firehose grows and capacity stays flat, the only thing that scales is deciding better.
You can’t fix everything, and you never could. The question is whether you’re fixing the right things: exposure, exploitability, reachability, and business context, with severity as one input and never the verdict. The winners won’t be the teams that find the most issues. They’ll be the teams that make the best decisions based on context. That’s what Legit has spent years building toward. BOD 26-04 just told the rest of the market it’s the only thing that counts.
Download our new whitepaper.