Get an overview of how secrets scanners work, and how Legit is dramatically reducing secret-scanning false positives.
As development environments grow more complex, applications increasingly communicate with many external services. When a software development project communicates with an external service, it utilizes a token or “secret” for authentication.
These tokens are the glue that keeps any modern application together, and there is a staggering volume and variety of them in code today. If these secrets leak, the consequences can be enormous. Hence, attackers consider them crown jewels and constantly look for ways to harvest them.
Identifying and securing these secrets has proven challenging, in part because of high rates of false positives. However, AI and ML hold promise in identifying secrets more accurately; our recent research has found they can reduce the rate of false positives by as much as 86%.
Types of secrets
Secrets in software are any sensitive data that takes part in the software development lifecycle (SDLC) and CI/CD processes that should be kept confidential to an organization.
The wide range of secret types and risks associated with exposed secrets through leaks include:
- Username and password: a classic authentication method. If discovered by a threat actor, they can be used to access other critical systems.
- API keys are unique identifiers that authenticate a user, developer, or calling program to an API. Their exposure could lead to unauthorized access or misuse of the services they unlock.
- SSH keys are digital signatures used for securely accessing remote systems. If compromised, they can also lead to unauthorized system access and potential breaches.
- Git credentials are used to access code repositories across third-party databases. If exposed, unauthorized code changes or theft might occur, impacting the development process or leading to a critical security incident.
Not all secrets are system credentials or specific code strings. Sometimes, developers inadvertently leave personally identifiable information (PII) like healthcare data, credit card numbers, or bank account information within the code. In many cases, this is “test” data that’s accidentally left but can still leave an organization vulnerable to a breach and heavy fines for compliance violations if it’s exposed.
Challenges of protecting secrets
Managing these secrets securely is no easy feat since they play a role in every step of the SDLC, from source code management (SCM) systems through CI/CD pipelines to cloud infrastructure. A common place for secrets to appear is in source code.
Our recent research indicates that, on average, 12 valid secrets are found per every 100 repositories. Once a secret reaches a Git-based repo, finding and removing it becomes incredibly challenging, as it may be tucked away, hiding in a side branch, and still copying itself onto every developer’s machine, possibly finding its way to the public domain.
Yet code repositories are far from the only place secrets can end up. Through mistakes or mismanagement, they can also make their way to artifacts and containers, build logs, cloud assets, and sometimes even wikis. These locations can pose an even more significant threat, as they are often intentionally public.
The role and limitations of secrets scanners
Keeping secrets safe involves increasing awareness of development teams, strengthening the security posture of all your SDLC assets, employing strict permissions policies, and using secrets scanners.
Secrets scanners were created to find leaks of such secrets before they reach malicious hands. They work by comparing the source code against predefined rules (regexes) that cover a wide range of secret types. Because they are rule-based, secrets scanners often trade between high false-positive rates on the one hand and low true-positive rates on the other.
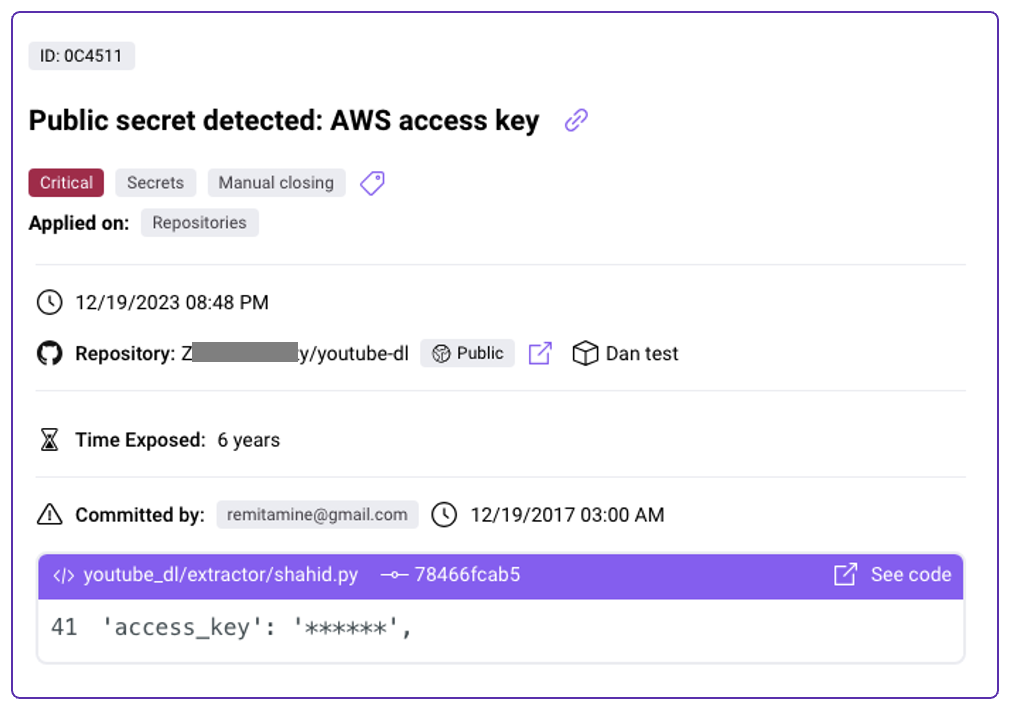
The inclination towards relaxed rules to capture more potential secrets results in frequent false positives, leading to alert fatigue among those tasked with addressing these alarms. Some scanners implement additional rule-based filters to decrease false alerts, like checking if the secret resides in a test file or whether it looks like a code variable, function call, CSS selection, etc., through semantic analysis.
However, these simple approaches, although tempting, result in many false negatives, as genuine secrets can fall under these criteria.
Reducing false alarms with AI
AI can play a role in overcoming this challenge. We at Legit have developed a machine learning model that can be directed at vast amounts of code and fine-tuned (trained) to understand the nuance of secrets and when they should be considered false-positive. Given a secret and the context in which it was introduced, this model knows whether it should be flagged. Using this approach will reduce the number of false positives while keeping true positive rates stable.
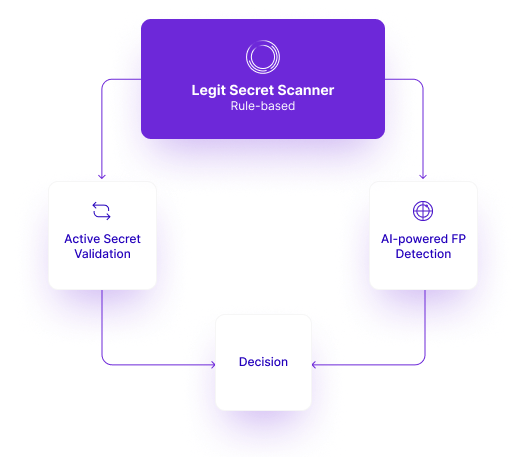
The overall solution also includes “Active Secret Validation,” which tries to validate whether a secret is valid or not to further increase the certainty we have in our predictions.
We tested the use of AI/ML on over 10,000 manually labeled samples from open-source projects, reducing false positives by 86% with negligible impact on true positives, meaning significant noise reduction and improved risk prioritization.
Protecting secrets without wasting time
Protecting secrets in code is a big challenge that’s only getting bigger. Addressing it is multi-layered, and scanners are only one layer. But this layer becomes much more efficient and effective when optimized with AI/ML, which drowns out excess noise.
Learn more about Legit’s secrets scanning capabilities.
You can also, for a limited time, request a Free Trial of the Legit Secrets Scanner.