-1.jpg)
As artificial intelligence (AI) and large language models (LLMs) like GPT become more entwined with our lives, it is critical to explore the security implications of these tools, especially the challenges arising from a lack of visibility into AI-generated code and LLM embedding in applications.
Understanding AI Code Assistants Like Github Copilot
It seems that AI is everywhere these days. One of the most rapidly trending applications of AI is using AI code assistants such as GitHub Copilot. It saves a lot of time for your developers and allows them to deliver a lot faster. It is also important to understand that AI code assistants pose significant security challenges.
The code generated by AI is often treated by developers as trusted and secure. It is no secret that many developers aid external resources as part of their daily job. For example, Stack Overflow is usually one of the first websites to visit whenever a developer encounters a question or a bug. It’s true that developers have been using copy-paste to write new code. But unlike Stack Overflow, code introduced by AI code assistants often work as-is. No need to modify variable names. This can cause developers to trust this code unquestioningly.
We strongly encourage organizations to adopt AI code assistance, but without gaining visibility over who is using it, your code assistant might introduce new security and compliance risks to your organization. If you use AI code assistants, It is strongly recommended that you have secure and reasonable policies and practices in place designed to prevent the use of a suggestion in a way that may violate the rights of others.
Introducing AI-generated Security Risks
Introducing vulnerable code at scale
Code assistants are engineered by assimilating millions of coding instances from across the internet. Considering the enormous volume of unchecked code, these assistants have analyzed and absorbed, it is unavoidable that they have been exposed to, and might have unintentionally assimilated, faulty code fraught with bugs. Research has unveiled that approximately 40% of the code generated by GitHub Copilot possesses vulnerabilities. Consequently, for certain vital and public facing applications, organizations need to implement stricter usage guidelines for code assistants or adopt an alternative approach to code review.
Copyrights considerations
-
The model that powers most of these code assistants is trained on a broad collection of publicly accessible code, including copyrighted code, and suggestions may resemble the code its model was trained on. Here’s some basic information you should know about these considerations:
-
Countries worldwide have provisions in their copyright laws that enable machines to learn, understand, and extract patterns, and facts from copyrighted materials, including software code. For example, the European Union, Japan, and Singapore have express provisions permitting machine learning to develop AI models. Other countries including Canada, India, and the United States also permit such training under their fair use/fair dealing provisions.
Gaining visibility over which developers from which country are using code assistants is a must in order to get in legal trouble, especially for multinational organizations.-
In some cases, suggestions from code assistants may match examples of code used to train the model. If a suggestion matches existing copyrighted code, there is a risk that using that suggestion could trigger claims of copyright infringement, which would depend on the amount and nature of code used, and the context of how the code is used. That is why responsible organizations and developers recommend that users employ code scanning policies to identify and evaluate potential matching code. You must gain visibility on which repositories are impacted by AI code assistants in order to enforce scanners continuously.
-
There are ways to avoid copyright issues using filters depending on each code assistant you use. For example, GitHub Copilot does include an optional code referencing filter to detect and suppress certain suggestions that match public code on GitHub.
Privacy and IP leak
Most code assistants provide suggestions based on the context of what you’re working on in your code editor. This requires temporarily transferring an ephemeral copy of various elements of that context to their servers. In most cases, it is guaranteed that the code or information sent is encrypted and never saved. However, we have seen cases before where misconfiguration on the vendor end revealed customers' information as well. This, among other reasons, has led companies like Apple and Samsung to restrict their employees from using AI code assistants to prevent private information leaks.
By knowing who uses code assistants at your organization, you can enforce different policies and ensure that adopting this disruptive technology won’t put your organization at risk.
Unraveling the Complications of LLM Embedding
LLMs, such as GPT, are increasingly being embedded in applications to enhance user experience and functionality, aiding in natural language understanding and generation, and automating various tasks. However, these models come with their own set of security concerns. OWASP has released its top 10 risks for LLM applications. Understanding the threats will emphasize how important it is to gain visibility and enforce guardrails over your LLM development.
OWASP LLM applications top 10:
-
Prompt Injection
-
Insecure Output Handling
-
Training Data Poisoning
-
Model Denial of Service
-
Supply Chain Vulnerabilities
-
Sensitive Information Disclosure
-
Insecure Plugin Design
-
Excessive Agency
-
Overreliance
-
Model Theft
So, indeed we can see the many risks that LLM can introduce in your application and organization. Each risk can be devastating, but fortunately, each risk can also be prevented. The key part of securing your LLM or your MLOps pipeline is visualizing it. By understanding the moving parts, the process your data goes through, and the way that input and output are sanitized, you can prevent the risk.
Conclusion
As the intertwining of AI and cybersecurity continues to deepen, so does the imperative to illuminate and secure the unseen recesses of AI-generated code and LLM embedding in applications. Cybersecurity Awareness Month serves as a reminder that AI is revolutionizing the software development world, yet it also presents an opportunity to solidify our defenses, enhance transparency, and navigate the mysterious yet thrilling world of AI.
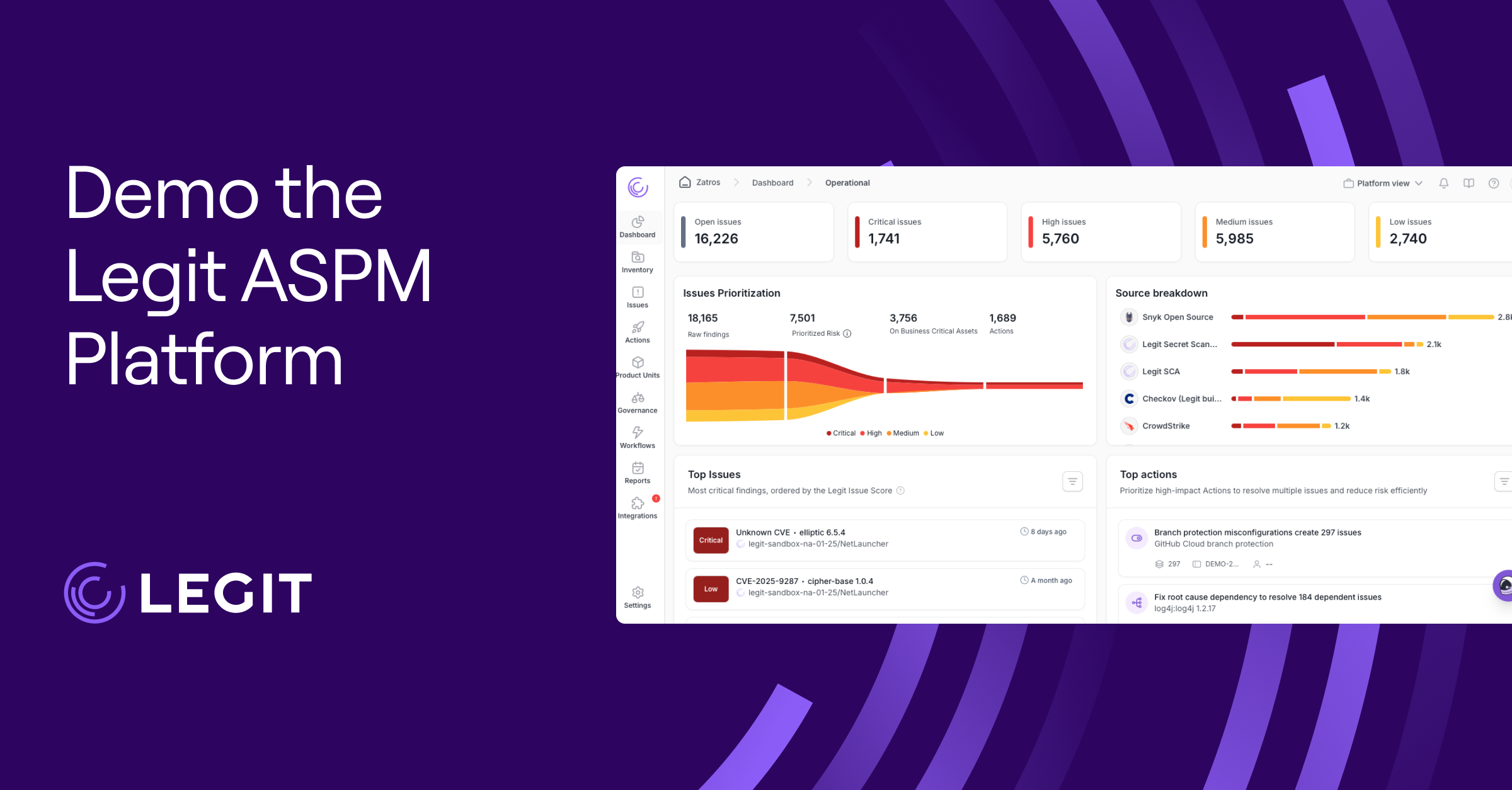
Use Legit Security for visibility and security of AI-Generated Code and Apps
Legit has introduced several new security controls, ensuring your development teams can integrate AI code assistants and embed LLM without exposing themselves to new risks.
Discover AI code assistants in your organization
Legit offers code generation detection and provides more robust insight into repositories accessible by users using code generation tools such as GitHub Copilot. Users can now quickly identify which repositories have been influenced by automatic code generation, providing a deeper understanding of their GenAI-affected code base. In addition, you can see when users install new code-generation tools. These capabilities are designed to provide more transparency and accountability, giving users more control over their code-generation processes.
Repositories Using LLM
The first step in secure LLM development is understanding where these models are developed. Legit Security detects LLM and GenAI development and enforces organization security policies. Legit can help discover LLM implementations that are potentially vulnerable to attack and prevent them from being in production.
To learn more about these and other broader capabilities of the Legit Security platform, book a demo.
Download our new whitepaper.